Cilium’s service LB based on eBPF/XDP
The first part introduced K8S service. Now, we can focus on Cilium’s service LB based on eBPF/XDP.
Cilium agent
Cilium service LB implements data path for all K8s service types via BPF.
- cilium-agent on each node watches kube-apiserver.
- cilium-agent observes the changes in K8S service.
- cilium-agent dynamically update BPF configuration according to changes in K8S service.
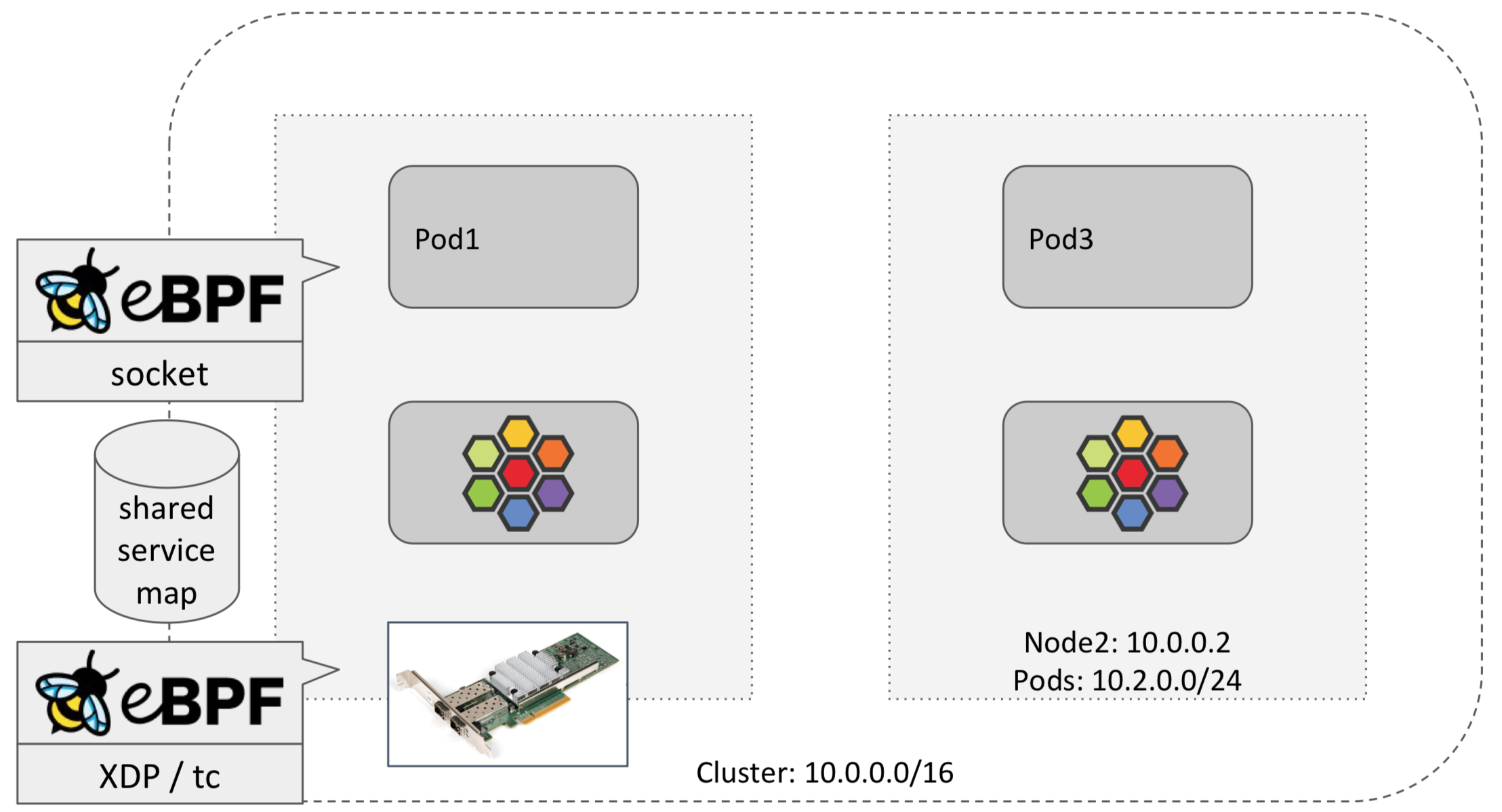
As the diagram shown above, there are two components realized the service
- Running on socket layer BPF program
- Running on tc/XDP layer BPF program
They share the same service map resource, which stores the mapping between service and backend pods.
Socket layer LB (East-West Traffic)
BPF_PROG_TYPE_SOCKET_FILTER was the first program type to be added to the Linux kernel. When attaching a BPF program to a raw socket, we can access to all the packets processed by that socket. Socket filter programs don’t allow you to modify the contents of those packets or to change the destination for those packets. They give us access to them for observability purposes only.
Socket layer implements for east-west traffic, which is in cluster traffic.
K8s Pods are still cgroup v1. Cilium mounts cgroup v2, attaches BPF to root cgroup. Hybrid use works well for root v2.
Implementation
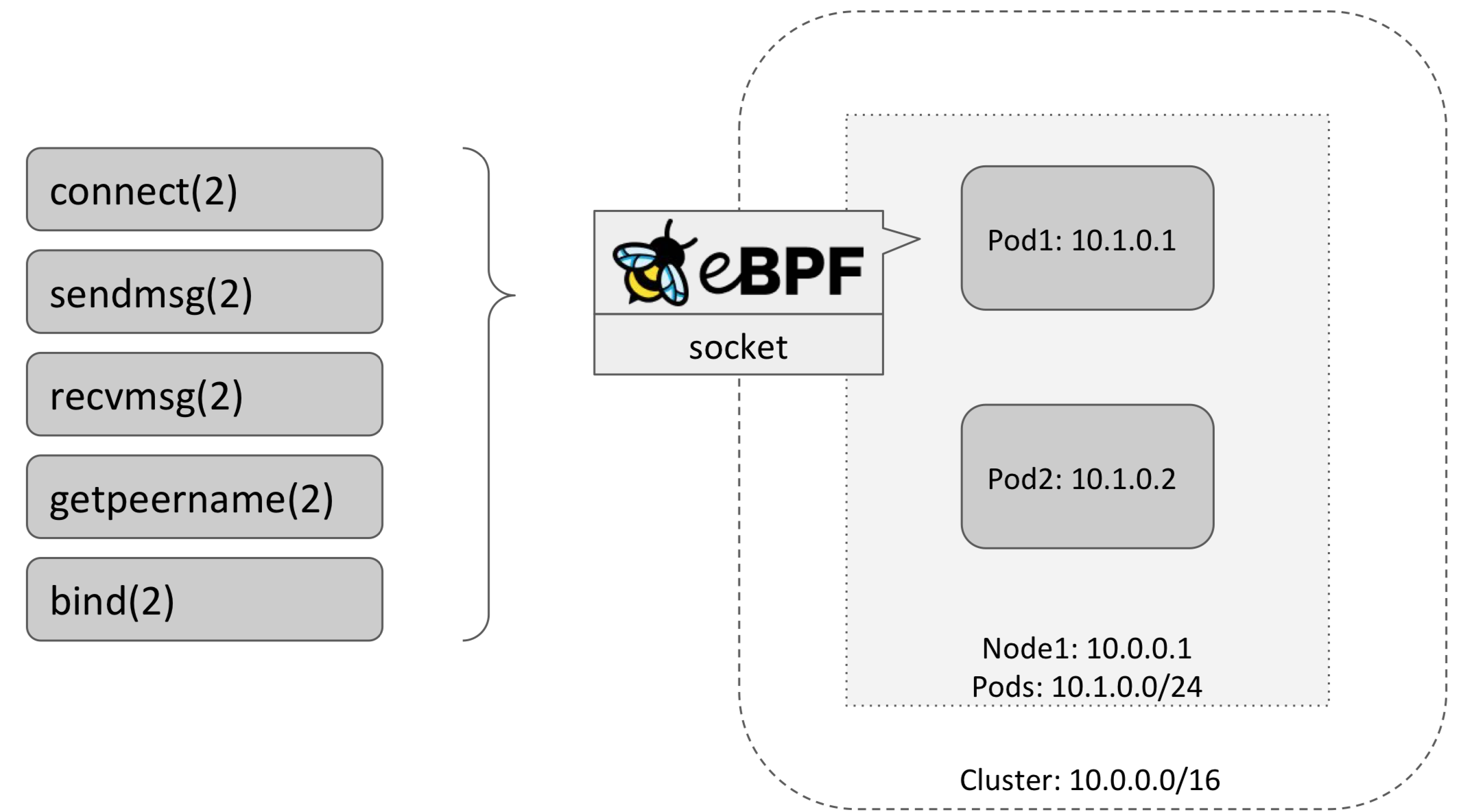
The implementation will attach BPF program to socket syscall hooks. Communicating to backend pod by using client. As diagram shown below, the hook includes connect(), sendmsg(), recvmsg(), getpeername() and bind() etc.
connect + sendmsgBPF programs do forward translation of struct sockaddr.recvmsg + getpeernameBPF programs revert translation.- The translation is based on socket structure, there is no packet-based NAT! Done for TCP + UDP on v4, v6, v4-in-v6.
- Application still think it connects to the service, but it actually connects to Pod IP.
Service lookup
Scoped lookup in service map for sock LB (vs tc/XDP) in order to permit different backends depending on node internal/external traffic. For example, if external traffic arrives to the node, we can forward it to local backend pod. It reduce the hop to backend pod of other node.
Wildcard lookup in service map for sock LB in order to expose service on local or loopback addresses.
Approach to translate all services on every cluster node at socket layer also faster than kube-proxy. There is no additional hops in network.
Bind
In addition, bind BPF program rejects application requests from binding to NodePort. Compared with generated packet being dropped in the protocol stack, bind rejection is more efficient.
There are two global functions crucially helps:
unique bpf_get_socket_cookie(): It’s mainly for UDP sockets, we hope every UDP flow is able to select the same backend pods.bpf_get_netns_cookie(): It distinguishes host netns and pod netns, for example, bind rejects when detects host netns. It also applies to serviceSessionAffinity to select the same backend pods in a certain time frame. Because cgroup v2 has no knowledge of netns, there is no Pod source IP in the context. This helper can get source IP, which can be source identifier.
BPF via tc/XDP (South-North Traffic)
Loading BPF programs with tc (traffic control) and XDP (eXpress Data Path), it controls south-north traffic. XDP hook is earlier, hence faster performance. tc hook is later and hence has access to the sk_buff structure and fields. BPF_PROG_TYPE_XDP programs allow us to write code that is executed very early on when a network packet arrives at the kernel. tc has better packet mangling capability. The BPF input context is a sk_buff for tc and not a xdp_buff for XDP.
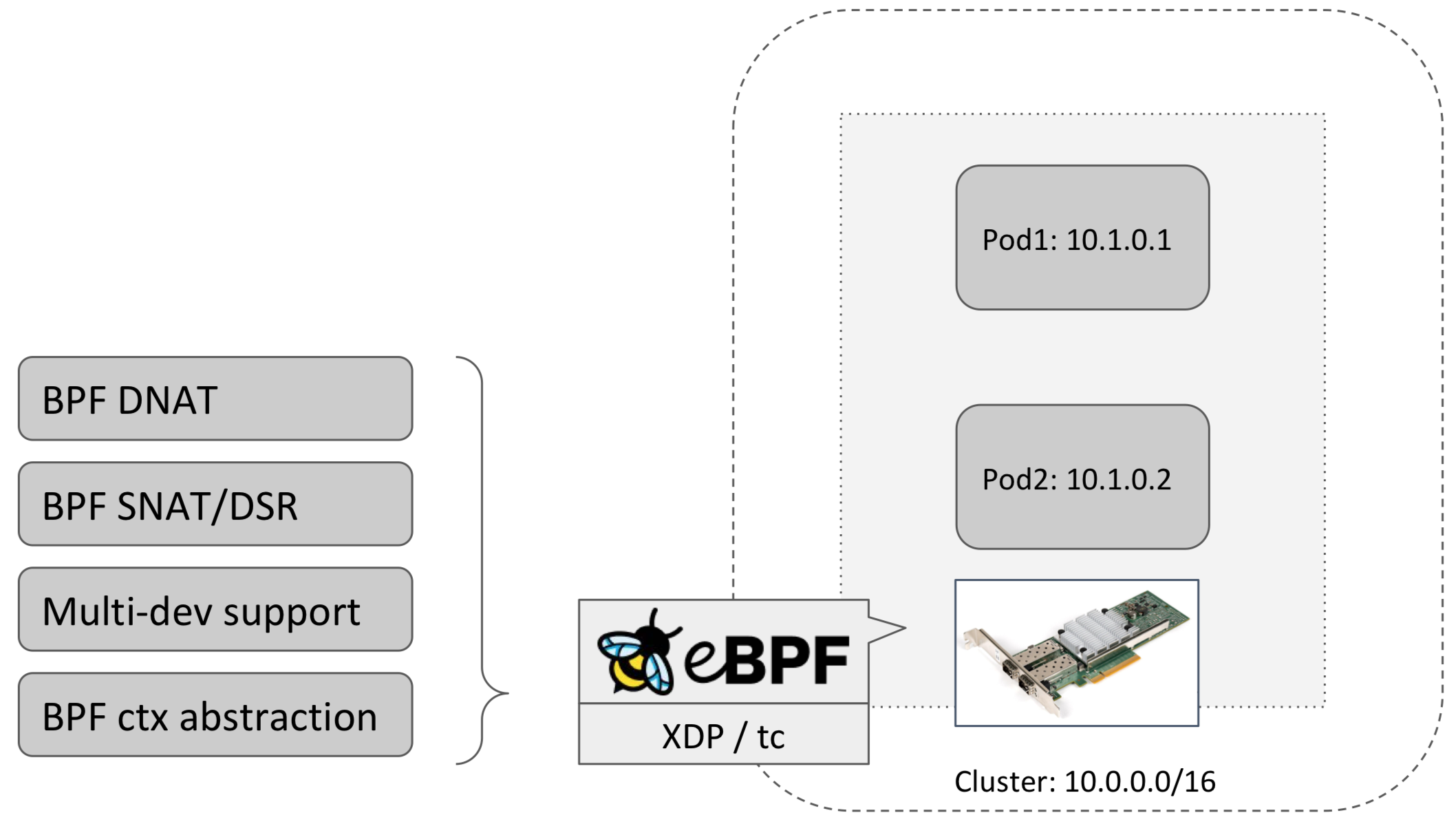
What BPF does is to forward the traffic to backend pod.
- if the backend pod is in the same node, apply DNAT
- if the backend pod is not in the same node, in addition, appy SNAT or DSR.
They are all packets manipulations.
BPF/XDP context generic
As diagram shown above, D/SNAT engine, DSR, conntrack etc., all implemented in tc BPF. For XDP support, the question was whether to abstract context or reimplement. Ended up refactoring almost all parts of our BPF code base to make it context generic. The rationale is to avoid bit rot, optimizations and fixes in generic code apply to both XDP and tc.
Inline ASM
Most helpers in skb context need inline equivalents for XDP. LLVM tends to optimize, which then fails verifier. Inline asm as rescue.
Avoid generic XDP on user side
v5.6 kernel was a milestone on XDP side: XDP for the masses on public cloud via AWS ENA & Azure hv_netvsc driver. For max support on variety of drivers though, only bare minimum features must be assumed: XDP_PASS/DROP/TX. Cilium only supports native XDP on user side. Generic XDP only utilized for CI purpose.
The reasons to avoid generic XDP two-fold: given this runs on every end node in the cluster, we cannot linearize every skb & bypass GRO.
Customized memory function
We found LLVM builtins end up as byte-wise operations for non-stack data. So we optimized mem{cpy,zero,cmp,move}(). Compile error for LLVM builtin functions. No context on efficient unaligned access.
In addition, in the benchmark testing, we observed that, under heavy traffic scenario, bpf_ktime_get_ns() is overhead noticeable under XDP. We made clock source selectable, switched to bpf_jiffies64(). It boostes the performance to approximately +1.1Mpps.
cb (control buffer)
tc BPF heavily uses skb->cb[] for passing data between tail calls in XDP. In order to pass data in XDP, we starts to use xdp_adjust_meta(). But there are two cons:
- missing driver support
- high rate of cache-misses
After switch to per-CPU scratch map, the performance increase roughly 1.2Mpps.
bpf_map_update_elem() in fast-path hitting bucket spinlock. If assumptions allow, can be converted to lock-free lookup first. If traffic coming from multiple cores, check if updating is needed without lock. If it exists already, just return.
bpf_fib_lookup() is expensive. It can be avoided and compiled out, e.g. for hairpin LB. It increase approximately +1.5 Mpps in our test env.
Also don’t gamble with LLVM & enforce BPF’s tail call patching via text_poke for static slots.